基本数据结构
标准数据类型¶
- 数字
- 字符串
- 列表
- 元组
- 集合
- 字典
不可变数据(3个): 数字, 字符串, 元组
可变数据(3个): 列表, 字典, 集合
数字¶
- 数字类型转换
int(x)将x转换为一个整数float(x)将x转换为一个浮点数complex(x)将x转换为一个复数, 实数部分为 x, 虚数部分为 0complex(x, y)将x和y转换为一个复数
- 数字运算
+-*/这是普通的除法, 返回的是一个浮点数//这是整除(向下取整)
- 数学函数
abs(x)返回数字的绝对值, 如abs(-10) 返回10ceil(x)返回数字的上入整数, 如math.ceil(4.1) 返回5exp(x)返回fabs(x)返回数字的绝对值的浮点数形式floor(x)返回数字的下舍整数, 如floor(4.9) 返回 4log(x, y)返回log10(x)返回- max(x1, x2,…) 返回给定参数的最大值, 参数可为序列
- min() 与上面类似
modf(x)返回x的整数部分和小数部分, 两部分的数值符号和x相同,整数部分以浮点型表示pow(x, y)返回- round(x[, n]) 返回x的四舍五入值, 如给出n值,则代表舍入到小数点后的位数
sqrt(x)返回
- 随机数函数
choice(seq)从序列的元素中随机挑选一个元素- randrange([start,] stop [,step]) 从指定范围内, 按指定基数递增的集合中获取一个随机数, 基数默认值为1
- random() 随机生成一个实数, 范围在
[0, 1)内 seed(x)改变随机数生成器的种子seedshuffle(lst)将序列的所有元素随机排序uniform(x, y)随机生成一个实数, 范围在[x, y]内
- 三角函数
degrees(x)将弧度转换为角度radians(x)将角度转换为弧度
字符串¶
索引¶

切片为左闭右开的区间(切片时,可以有三个参数:[开始处索引值,] 结束处索引值 [, 步长]; 将步长设为负数, 开始处与结束处索引值选合适值可实现反向迭代的效果)
转义字符¶
| 字符 | 含义 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠 |
| \’ | 单引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数, y代表0~7的字符, 如:\o12代表换行 |
| \xyy | 十六进制数, 以\x开头, yy代表字符, 如:\x0a代表换行 |
| \other | 其他的字符以普通格式输出 |
运算符¶
| 操作符 | 描述 |
|---|---|
| + | 字符串连接 |
| * | 重复输出字符串 |
| [] | 通过索引获取字符串中的字符 |
| [:] | 截取字符串中的一部分(如果步长为负, 则start和stop的索引值依然为原序列的索引值, 而不是将序列反转后的索引值) |
| in | 成员运算符 -如果字符串中包含给定的字符返回True |
| not in | 成员运算符 -如果字符串中不包含给定的字符返回True |
| r/R | 原始字符串 -所有的字符串都是直接按照字面的意思来使用, 没有转义特殊或不能打印的字符, 需在字符串的第一个引号前加上R\r |
| % | 格式字符串 |
字符串的格式化¶
-
与
C语言类似, 例如:1
print("My name is %s and weight is %d kg!" % ('Zara', 21))
-
f-string
-
str.format()
字符串内建函数¶
| 方法 | 描述 |
|---|---|
| string.capitalize()/title() | 把字符的第一个字符大写/标题化[1] |
| string.center(width) | 返回一个原字符串居中, 并使用空格填充至长度width的新字符串(填充符可以换) |
| string.count(str, beg=0, end=len(string)) | 返回str在string里面出现的次数, 如果beg或end指定则返回指定范围内str出现的次数 |
| string.decode(encoding=‘utf-8’, errors=‘strict’)/string.encode() | 以encoding指定的编码格式解码/编码string, 如果出错则默认报一个ValueError的异常, 除非errors指定的是ignore或replace |
| string.endswith(obj, beg=0, end=len(string))/startswith() | 检查字符串是否以obj结束/开始, 如果beg或end指定则检查指定范围内是否以obj结束,如果是, 返回True, 反之返回False |
| string.find(str, beg=0, end=len(string))[lfind, rfind] | 检测str是否包含在string中(beg和end等效); 如果在, 返回开始的索引值, 不在返回-1 |
| string.format() | 格式化字符串 |
| string.index(str, beg=0, end=len(string))[lindex, rindex] | 和find()一样, 只不过查找不到时返回一个异常 |
| string.isalnum()/isalpha()/ isdecimal()/isdigit()/islower()/ isnumeric()/isspace()/isupper()/ istitle() |
检测是否符合预设格式(字母或数字/字母/十进制数字/数字/小写/数字字符/空格/大写/标题) |
| string.join(seq) | 以string作为分隔符, 将seq中的所有元素合并为一个新的字符串 |
| string.ljust(width)/rjust(width)[zfill(width)] | 返回一个原字符串左对齐/右对齐, 并使用空格填充至长度width的新字符串(填充符可以换)/zfill的填充符不可以换 |
| string.lower()/upper()/swapcase() | 返回一个原字符全部小写/大写/翻转大小写的新字符 |
| string.partition(str)[rpartition] | 从str出现的第一个位置起, 把字符串string分成一个三元素的元组(string_pre_str, str, string_post_str), 如果string里不包含str, 则string_pre_str == string |
| string.replace(str1, str2, num=string.count(str1)) | 把string中的str1替换成str2, 如果num指定, 则替换不超过num次 |
| string.split(str=“”, num=string.count(str)) | 以str为分隔符切片string, 如果num有指定值, 则仅分隔num+1个子字符串 |
| string.lstrip([obj])/rstrip()/strip() | 截掉string左边/右边/两边的obj |
| string.maketrans(intab, outtab)/str.translate(str, del=“”) | maketrans()用于创建字符映射的转换表, intab是需要转换的字符, outtab是转换后的字符(其参数可以是一个字典, 但每个字符应该一一对应); translate()方法使用转换表进行转换 |
列表与元组¶
操作符¶
| 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| [“hi”] * 4 | [“hi”, “hi”, …] | 重复 |
| 3 in [1, 2, 3] | True | 检测是否存在 |
| for x in [1, 2, 3]: print x | 1 2 3 | 迭代 |
截取与访问¶
与字符串相似
函数&方法¶
| 方法 | 描述 |
|---|---|
| cmp(list1, list2) | 比较两个列表的元素 |
| max(list)/min(list) | 返回元素的最大值/最小值 |
| list(seq) | 将元组转换为列表 |
| tuple(seq) | 将列表转换为元组 |
| list.append(obj) | 在末尾添加新的对象 |
| list.count(obj) | 统计出现的次数 |
| list.extend(seq) | 一次性追加多个值 |
| list.index(obj) | 找出某个值第一个匹配项的索引位置 |
| list.insert(index, obj) | 将对象插入列表 |
| list.pop([index=-1]) | 移除列表中的一个元素(默认为最后一个), 并返回这个值 |
| list.remove(obj) | 移除列表中的某个值的第一个匹配项 |
| list.reverse() | 反向列表中的元素 |
| list.sort(cmp=None, key=None, reverse=False) | 对列表进行排序 - cmp—排序的算法 - key–指定参与排序的对象 - reverse—排序规则, True降序, False升序 |
元组中的元素不可以进行变更, 所以无法向列表一个进行以上表格下半部分的操作
注: 列表和元组的迭代可以通过enumerate函数来实现索引-值对的迭代
字典与集合¶
函数&方法¶
| 方法 | 描述 |
|---|---|
| cmp(dict1, dict2) | 比较 |
| len(dict) | 长度 |
| str(dict) | 输出字典可打印的字符串表示 |
| type(variable) | 返回输入的变量类型, 如果变量是字典就返回字典类型 |
| pop(key[, default]) | 删除字典给定键key所对应的值, 返回值为被删除的值; key值必须给出, 否则返回default |
| popitem() | 返回并删除字典中的最后一对键/值 |
| dict.clear() | 删除字典内的所有元素 |
| dict.copy() | 返回一个字典的浅复制(深复制父对象[一级目录], 浅复制子对象[二级目录]) |
| dict.fromkeys(seq[, val]) | 创建一个新词典, 以序列seq中的元素做字典的键, val做字典的值 |
| dict.get(key, default=None) | 返回指定键的值, 如果值不在字典中返回default值 |
| dict.has_key(key) | 如果键在字典里返回True, 反之返回False |
| dict.items() | 以列表返回可遍历的(键, 值)元组数组**[可遍历]** |
| dict.keys() | 以列表返回一个字典所有的键 |
| dict.values() | 以列表返回字典中所有的值 |
| dict.setdefault(key, default=None) | 与get()类似, 如果不在, 将会添加键并将值设为default |
| dict.update(dict2) | 把字典dict2的键/值对更新到dict中 |
| set.add(key) | 添加键 |
| set.remove(key) | 移除键 |
创建集合和字典的差异¶
- 创建一个空字典
dict = {} - 创建一个空集合
set = set()
Python数据类型转换¶
| 函数 | 作用 |
|---|---|
| int(x[,base]) | 将x转换为一个整数 |
| long(x[,base]) | 将x转换为一个长整数 |
| float(x) | 将x转换为一个浮点数 |
| complex(real[,imag]) | 创建一个复数 |
| str(x) | 将x转换为字符串 |
| repr(x) | 将x转换为表达式字符串(将对象转化为供解释器读取的形式)[2] |
| eval(str) | 用来计算在字符串中的有效Python表达式, 并返回一个对象 |
| tuple(s) | 将序列s转换为一个元组 |
| list(s) | 将序列s转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典; d必须是一个序列(key, value)元组 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符(ASCII字符) |
| unichr(x) | 将一个整数转换为Unicode字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
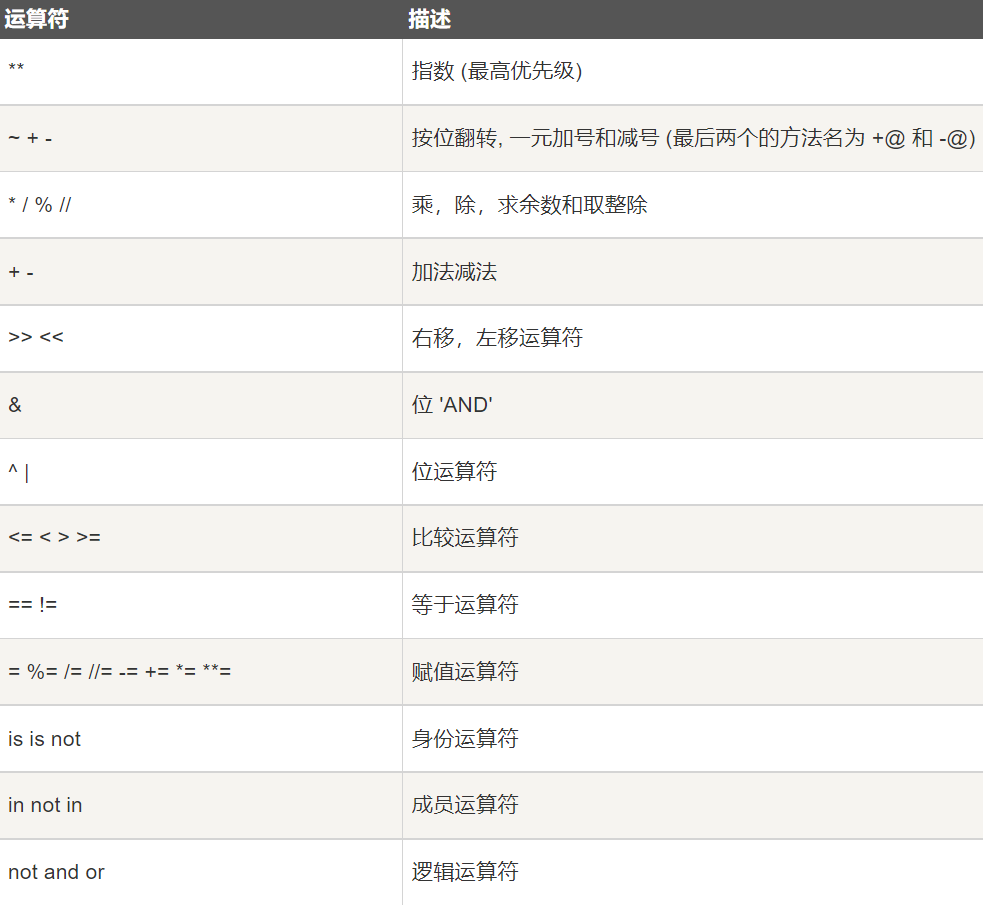
运算符小结¶
-
比较运算符 (
==等于,>=大于等于,<=小于等于,!=不等于,>/<大于/小于) -
赋值运算符 (
=赋值,+=/-=/*=//=///=/%=/**=相应运算后赋值给原变量,:=海象运算符, 可在表达式内部给变量赋值[Python3.8新增])1
2
3# 海象运算符示例(可以避免一些运算算两次)
if (n := len(a)) > 10:
pass -
位运算符 (
&按位与,|按位或,~按位取反,^按位异或,>>/<<右移动运算符/左移动运算符) -
逻辑运算符 (
and与,or或,not非) -
成员运算符 (
in在,not in不在) -
身份运算符 (
is是[指id()后的标识符相同],is not否)
运算符优先级¶
数据结构扩展¶
堆栈¶
将列表当作堆栈来使用(类似用C实现的链栈)
1 | # 例 |
队列¶
将列表当作队列使用(同样类似队列的链表实现)
1 | # 例 |
遍历技巧¶
-
在进行字典遍历时, 可以使用
items()方法将关键字和值同时得到 -
在序列中遍历时, 可以使用
enumerate()函数将索引值和对应值同时得到 -
在遍历两个或更多的序列时, 可以使用
zip()将其组合1
2
3
4
5
6
7
8questions = ['name', 'quest', 'favorite color']
answers = ['lancelot', 'the holy grail', 'blue']
for q, a in zip(questions, answers):
print('What is your {0}? It is {1}'.format(q,a))
# What is your name? It is lancelot
# What is your quest? It is the holy grail
# What is your favorite color? It is blue -
反向遍历一个序列, 可以使用
reversed()函数(也可以巧用切片, 用空间换时间) -
顺序遍历一个序列, 可以使用
sorted()函数返回一个已经排序的序列
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Ardenet's Blog!
相关推荐

2022-04-23
模块详解
模块¶ 定义¶ 模块是一个包含所有你定义的函数和变量的文件, 其后缀名为.py 模块可以被其他的程序引入, 以使用该模块中的函数等功能; 这也是使用Python标准库的方法 用法¶ import语句¶ 语法: import module1[, module2[,... moduleN]] 作用: 解释器会在搜索路径下寻找导入的模块, 找到则导入, 找不到则报错(一个模块只会被导入一次, 不论使用了几次import) 搜索路径: 在Python编译或安装时确定的, 被保存在sys模块中的path变量中; sys.path输出的是一个列表, 其中第一项是空字符串, 代表当前目录(运行脚本时, 脚本所在目录) from...import语句¶ 语法: from modname import name1[, name2[,... nameN]] 作用: 从模块中导入一个指定的部分到当前命名空间中 from...import *语句¶ 语法: from modname import * 作用: 把一个模块的所有内容全部导入到当前的命名空间中(PEP8不推荐这种方式) 深入模块¶...
2022-04-23
函数详解
函数定义¶ 以def关键词开头, 后街函数标识符名称和圆括号() 任何传入参数和自变量必须放在圆括号中间 函数的第一行语句可以选择性的使用文档字符串—用于存放函数说明 函数内容以冒号起始并且缩进 return [表达式]结束函数, 选择性的返回一个只给调用方; 不带表达式的return相当于返回None 参数传递¶ 在Python中, 类型属于对象, 变量是没有类型的, 如a = [1, 2, 3]以上代码中, [1, 2, 3]是list类型, 而a是没有类型的,他仅仅是一个对象的引用(指针) 可更改与不可更改对象¶ 不可变类型: string, tuple和number是不可更改对象 可变类型: list, dict等是可更改对象 传递参数过程: 不可变类型: 类似值传递 可变类型: 类似引用传递 补充: 不可变对象是指对象本身不可变, 但变量的对象引用可变而可变对象是指对象内容可变, 但变量的对象引用不会改变 参数类型¶ 必备参数(位置参数) 必备参数必须以正确的顺序传入函数, 调用时的数量必须和声明时一样 12def func(param): p...
2022-04-23
正则表达式
概念¶ 正则表达式是一种用来匹配字符串的强有力的武器。它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的 模式¶ 模式 描述 ^ 匹配字符串的开头 $ 匹配字符串的末尾 . 匹配任意字符 \ 是之后的表示式失效, 仅匹配其字面字符 [...] 用来表示一组字符, 单独列出[amk] 匹配 ‘a’, ‘m’ 或 ‘k’ [^...] 匹配不在[]中的字符 [...-...] 匹配一个范围(如果想匹配一个-, 则可以将其放在括号开头或结尾) * 匹配 0 个或多个表达式 + 匹配 1 个或多个表达式 ? 匹配 0 个或 1 个表达式, 非贪婪方式 {n} 精确匹配 n 个表达式 {n, m} 匹配 n 到 m 次表达式, 贪婪方式( 若无 m, 如{n,}, 则匹配 n 到无穷多个表达式) a | b 匹配 a 或 b (...) 对正则表达式分组并记住匹配的文本 (?imx...) 正则表达式包含三种可选标志: i, m 或 x; 只影...
2022-04-23
基本语法
编码¶ 默认情况都采用UTF-8编码, 当然也可以为源码文件制定不同的编码 1# -*- coding: cp-1252 -*- 输入/输出¶ print() 函数可接受多个字符串, 用“,”隔开, 或用“+”连接字符串; 同时它也可以打印整数或计算结果, 同时它可以接受参数 end来指定以什么字符结尾 , 隔开: 会在输出中原本“,”的地方补一个空格 + 连接: 不会在“+”的地方补空格 input() 函数可以让用户输入字符串, 并存放在一个变量里, 同时它可以接受一个参数用于提示用户输入, 例: 12neme = input('Please enter your name:')print('hello,', name) 注释与缩进¶ 单行注释: 以 # 开头的语句是注释 多行注释: 用 '''或 """括住的部分属于多行注释, 一般位于文件, 类, 函数开头的多行注释会被解释为 DocString 缩进: PEP8 规定的缩进为4个空格 注: 当然可以使用任意个数的空格来代表...
2022-04-23
面向对象编程
基本思想¶ OOP把对象作为程序的基本单元, 一个对象包含了数据和操作数据的函数 面向过程的程序设计将计算机程序视为一系列命令的集合, 即一组函数的顺序执行; 而面向对象的程序设计将计算机程序视为一组对象的集合, 而每个对象都可以接收其它对象发过来的消息, 并处理这些消息, 程序的执行就是一系列消息在各个对象之间传递 基础概念¶ 类(classs): 自定义的对象数据类型, 一类对象的抽象模板 方法(Method): 对象对应的关联函数 实例(Instance): 由抽象模板生成的具体对象所以, 面向对象的设计思想是抽象出Class, 根据Class创建Instance 类变量: 定义在类中且在函数体之外的变量; 类变量在整个实例化的对象中是公用的 实例变量: 在类的声明中, 属性是用变量类表示的, 这种变量就称为实例变量 局部变量: 定义在方法中的变量, 只作用于当前实例的类(当前对象) 数据对象: 类变量或实例变量用来处理类及其实例对象的相关数据 方法重写: 对从父类继承的方法的重写或覆盖 基础语法¶ 定义类通过class关键字, 其后紧接的是类名; 之后可以加括号, 在...
2022-04-23
Python解释器
CPython: 官方开发的 Python 解释器, 使用 C语言 开发 IPython: 基于 CPython 解释器开发的, 在交互方式上有所增强(CPython用 >>> 作为提示符, 而IPython用 In [序号]: 作为提示符) PyPy: 采用 JIT技术, 对 Python 代码进行 动态编译 (不是解释), 所以可以显著提高Python代码的执行速度 Jython: 运行在 Java 平台上的Python解释器,可以直接把 Python 代码编译成 Java 字节码执行 IronPython: 运行在微软 .NET 平台上的Python解释器, 可以直接把 Python 代码编译成 .NET 的字节码
评论